문제
N개의 수가 주어졌을 때, 이를 오름차순으로 정렬하는 프로그램을 작성하시오.
입력
첫째 줄에 수의 개수 N(1 ≤ N ≤ 10,000,000)이 주어진다. 둘째 줄부터 N개의 줄에는 수가 주어진다. 이 수는 10,000보다 작거나 같은 자연수이다.
출력
첫째 줄부터 N개의 줄에 오름차순으로 정렬한 결과를 한 줄에 하나씩 출력한다.
시간 제한
- Java 8: 3 초
- Java 8 (OpenJDK): 3 초
- Java 11: 3 초
- Kotlin (JVM): 3 초
- Java 15: 3 초
메모리 제한
- Java 8: 512 MB
- Java 8 (OpenJDK): 512 MB
- Java 11: 512 MB
- Kotlin (JVM): 512 MB
- Java 15: 512 MB

수를 하나씩 입력받아서 오름차순 정렬하여 다시 하나씩 출력하는 문제이다.
먼저 가장 단순하게
1. 데이터를 입력 수만큼 list에 append 해서 넣어준다.
2. sort를 쓴다.
n = int(input())
data = []
for i in range(n):
data.append(int(input()))
data.sort()
for i in data:
print(i)
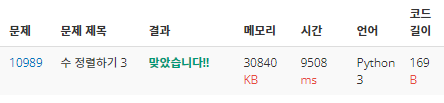
결과는

돌려보지도 못한 채 메모리 초과가 떴다.
그다음 우리는 최근 2개의 매우 빠른 정렬 알고리즘을 공부했다.
우선 조건이 자연수인 숫자만 들어오며 정렬되지 않은 데이터, 중복을 허용하는 데이터이기 때문에
계수 정렬을 떠올렸다.(Count Sort)
2022.09.17 - [Algorithm/이것이 코딩테스트다] - [Python][이코테] 계수 정렬
[Python][이코테] 계수 정렬
계수 정렬 계수 정렬(count sort)은 특정한 조건이 부합할 때만 사용할 수 있지만 매우 빠른 정렬 알고리즘이다. 사용하기 좋은 조건은 모든 데이터가 정수 데이터의 크기 범위가 제한되어 정수 형
baby-dev.tistory.com
n = int(input())
data = []
for i in range(n):
data.append(int(input()))
count = [0]*(max(data)+1)
for i in range(len(data)):
count[data[i]] += 1
for i in range(len(count)):
for j in range(count[i]):
print(i)하지만 역시나

메모리 초과였다.
그다음 조건 상관없이 빠른 퀵 정렬을 사용해 봤다.
2022.09.13 - [Algorithm/이것이 코딩테스트다] - [Python][이코테] 퀵 정렬
[Python][이코테] 퀵 정렬
퀵 정렬 퀵 정렬은 이름대로 굉장히 빠른 정렬을 해주는 알고리즘이다. 또한 굉장히 많이 쓰인다. 기준 데이터를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾼다. 이게 퀵 정렬
baby-dev.tistory.com
n = int(input())
data = []
for i in range(n):
data.append(int(input()))
def q_sort(array):
if len(array) <= 1:
return array
pivot = array[0]
tail = array[1:]
left_side = [x for x in tail if x <= pivot]
right_side = [x for x in tail if x>pivot]
return q_sort(left_side) + [pivot] + q_sort(right_side)
arr = q_sort(data)
for i in arr:
print(i)
이제 내가 배운 빠른 정렬 알고리즘은 다 썼다.
조금 더 생각하다가 결국 못 참고 구글에 검색을 해봤더니
입력받을 때 append( )를 사용한 게 잘못이라고 한다.
append( )를 사용하면 메모리 재할당이 이루어져서 메모리를 효율적으로 사용하지 못한다고 한다.
지금의 조건의 경우에는 수의 개수 N(1 ≤ N ≤ 10,000,000)이 천만 개까지 추가될 수 있어서 append로 추가를 해주면 메모리를 굉장히 비효율적으로 사용하게 된다.
이를 위해선
import sys
sys.stdin.readline( )
위의 방법을 이용해서 값을 입력받으면 input( )이나 append( ) 보다 훨씬 빠른 속도와 효율적인 메모리로 값을 입력할 수 있다.
import sys
n = int(input())
data = [0] * 10001
for _ in range(n):
data[int(sys.stdin.readline())] += 1
for i in range(10001):
for j in range(data[i]):
print(i)
sys.stdin.readline( )을 사용하였고
자연수, 중복 값있는 데이터를 처리하기 좋은 계수 정렬을 같이 사용했다.
data의 길이가 10001개인 이유는 각 줄에 입력되는 숫자의 최대 수는 10000이기 때문이다.
그래서 10001개의 각 값을 인덱스로 갖는 배열을 선언하고
예를 들어서 50이라는 숫자가 입력되면
data[50] += 1 을 해주어서 50이라는 숫자의 중복된 개수까지 파악할 수 있게 한다.
이후 10001번의 반복문을 통해 각 data[i]의 값만큼 반복하여 중복된 숫자까지 정렬하여 출력하면 끝.
'Algorithm > 백준' 카테고리의 다른 글
| [Python] 백준 1181번 - 단어 정렬 (0) | 2022.10.04 |
|---|---|
| [Python] 백준 11050번 - 이항 계수 1 (0) | 2022.10.01 |
| [Python] 백준 2231번 - 분해합 (1) | 2022.09.20 |
| [Python]백준 2908번 - 상수 (0) | 2022.09.13 |
| [Python] 백준 1157번 - 단어 공부 (0) | 2022.08.24 |




댓글