1장 데이터 입·출력 구현
그래프
무방향 그래프 간선 개수 : n(n-1)/2
방향 그래프 간선 개수 : n(n-1)
트리
순회
- 전위 순회 (PreOrder)
- Root, Left, Right
- 뿌리 먼저 방문
- 중위 순회 (InOrder)
- Left, Root, Right
- 왼쪽 하위 노드 방문 후 뿌리 방문
- 후위 순회 (PostOrder)
- Left, Right, Root 순
- 하위 노드 모두 방문 후 뿌리 방
A
/ \
B C
/ \ \
D E F
/ / \
G H I
- 전위 순회 (Pre-order Traversal)
- 순서: A → B → D → E → G → C → F → H → I
- 설명: 루트(A)를 먼저 방문, 왼쪽 서브트리(B-D-E-G)를 방문, 그리고 오른쪽 서브트리(C-F-H-I)를 방문합니다.
- 중위 순회 (In-order Traversal)
- 순서: D → B → G → E → A → H → F → I → C
- 설명: 왼쪽 서브트리(D-B-G-E)를 먼저 방문, 그 다음 루트(A), 마지막으로 오른쪽 서브트리(H-F-I-C)를 방문합니다.
- 후위 순회 (Post-order Traversal)
- 순서: D → G → E → B → H → I → F → C → A
- 설명: 왼쪽 서브트리(D-G-E-B)를 먼저 방문, 그 다음 오른쪽 서브트리(H-I-F-C), 마지막으로 루트(A)를 방문합니다.
수식 표기법
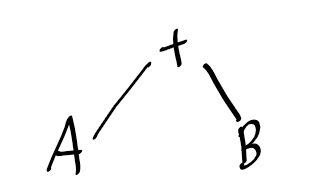
해당 A+B를 트리구조로 표현하면 위와 같다.
이를 전위(Prefix)수식, 후위(Postfix)수식으로 바꾸거나 중위(Infix)로 돌리는 방법.
Infix -> Prefix / Postfix

Postfix / Prefix -> Infix
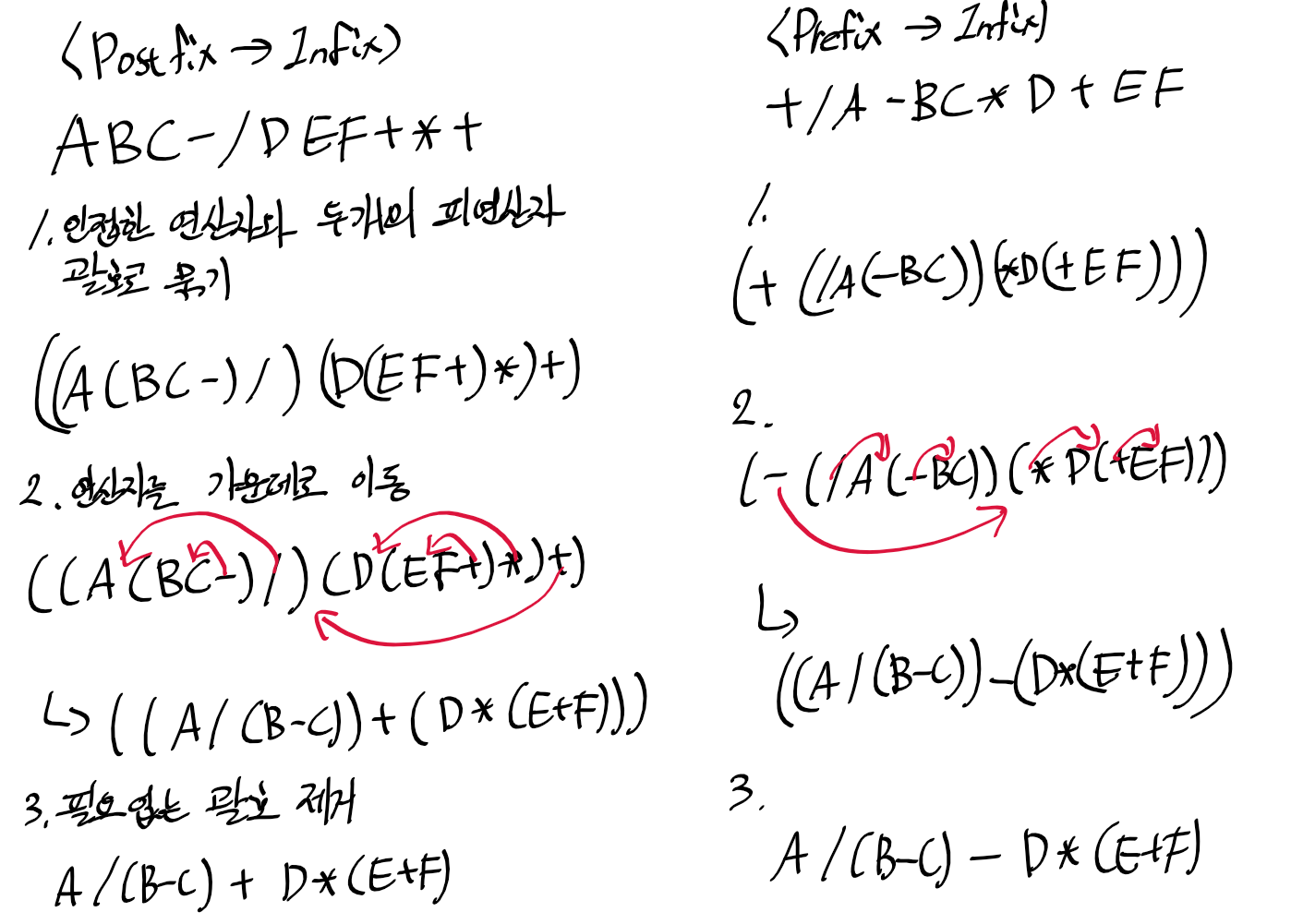
정렬
삽입 정렬
시간복잡도 : O(N²)
i번째 값을 0~i-1까지 비교하며 변경
1. 1번째 값과 0번째 값 비교하고 삽입 후 뒤로 밀기
2. 2번째 값을 0번째 값과 비교, 2번째 값을 1번째 값과 비교, 삽입 후 뒤로 밀기
3. 3번째 값을 0번째 값과 비교, 3번째 값을 1번째 값과 비교, 3번째 값을 2번째 값과 비교, 삽입 후 뒤로 밀기
...

선택 정렬
시간복잡도 : O(N²)
n개의 레코드 중에서 최소값을 찾아 첫번째 위치에 놓고, 나머지 (n-1)개 중에서 다시 최소값을 찾아 두번째 레코드 위치에 놓는 방식을 반복하는 방식
1. 0과 1~n-1을 계속 비교
2. 1과 2~n-1을 계속 비교
...
n. i와 i+1 ~n-1을 계속 비교
버블 정렬
시간복잡도 : O(N²)
인접한 두 개의 레코드 값을 비교하여 서로 교환

퀵 정렬
- 시간복잡도
- 평균 : O(nlog₂n)
- 최악 : O(N²)
- 하나의 파일을 부분적으로 나누어 가면서 정렬하는 방법
- 정렬 방식중 가장 빠름
- 스택 사용
- 분할 정복(Divide & Conquer)
- 피봇 (Pivot) 사용
힙 정렬
- 완전 이진트리를 이용한 정렬 방식
- 시간복잡도 : O(nlog₂n)
2-Way 합병 정렬 (Merge Sort)
- 이미 정렬된 두 개의 파일을 한 개의 파일로 합병하는 방식
71, 2, 38, 5, 7, 61, 11, 26, 53, 42 를 2-way 합병 정렬로 정렬
1회 : 두 개씩 묶은 후 각각의 묶음 안에서 정렬
(71, 2) (38, 5) (7, 61) (11, 26) (53, 42)
↓
(2, 71) (5, 38) (7, 61) (11, 26) (42, 53)
2회 : 묶여진 묶음을 두 개씩 묶은 후 각각의 묶음 안에서 정렬
(2, 71, 5, 38) (7, 61, 11, 26) (42, 53)
↓
(2, 5, 38, 71) (7, 11, 26, 61) (42, 53)
3회
(2, 71, 5, 38, 7, 61, 11, 26) (42, 53)
↓
(2, 5, 7, 11, 26, 38, 61, 71) (42, 53)
4회
(2, 5, 7, 11, 26, 38, 61, 71, 42, 53)
↓
2, 5, 7, 11, 26, 38, 42, 53, 61, 71
기수 정렬 (Radix Sort = Bucket Sort)
- 큐를 이용하여 자릿수 별로정렬
- 같은 수 또는 같은 문자끼리 그 순서에 맞는 버킷에 분배하였다가 버킷의 순서대로 레코드를 꺼내어 정렬
- 시간복잡도 : O(dn)
검색 - 이분 검색 / 해싱
이분 검색
앞과 끝의 중간을 찾는 검색 방법 (=이분 탐색)
mid = (first + last) / 2 (정수만 취함)
예 1 ~ 100 에서 15를 찾는데 걸리는 횟수
- (1+100) / 2 = 50.5 (= 50) -> 1회
- 50 은 찾으려는 15보다 크다.
- 값은 1 ~ 49사이
- (1+49) / 2 = 25 -> 2회
- 25는 찾으려는 15보다 크다
- 값은 1 ~ 24 사이
- (1 + 24) / 2 = 12.5 ( =12) -> 3회
- 12는 찾으려는 15보다 작다.
- 값은 13 ~ 24 사이
- (13 + 24) / 2 = 18.5 (= 18) -> 4회
- 18은 찾으려는15보다 크다.
- 값은13 ~ 17 사이
- (13 + 17) / 2 = 15 -> 5회
총 5회 비교
해싱
해시 테이블
- 버킷
- 슬롯
- Collision (충돌 현상)
- Synonym
- Overflow
해싱 함수
- 제산법(Division)
- 제곱법(Mid-Square)
- 폴딩법 (Folding)
- 기수 변환법 (Radix)
- 대수적 코딩법 (algebraic Coding)
- 숫자 분석법 (Digit Analysis, 계수 분석법)
- 무작위법 (Random)
Collision (충돌현상) 해결 방법
- 체이닝 (Chaining)
- 개방 주소법 (Open Addressing)
- 재해싱 (Rehashing)
데이터 베이스
스키마
- 스키마는 데이터베이스를 구성하는 데이터 개체(Entity), 속성(Attribute), 관계(Relationship) 및 데이터 조작시 데이터 값들이 갖는 제약 조건 등에 관해 전반적으로 정희
- 외부 스키마
- 사용자나 응용 프로그래머가 각 개인의 입장에서 필요로 하는 데이터베이스의 논리적 구조를 정의한 것
- 개념 스키마
- DB의 전체적인 논리적 구조로서, 모든 응용프로그램이나 사용자들이 필요로 하는 데이터를 종합한 조직 전체의 DB로 하나만 존재
- 개체간의 관계와 제약조건을 나타내고, DB의 접근 권한, 보안 및 무결성 규칙에 관한 명세를 정의
- 내부 스키마
- 물리적 저장장치의 입장에서 본 DB구로조서, 실제로 DB에 저장될 레코드의 형식을 정의하고 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등을 나타냄
2장 통합 구현
3장 제품 소프트웨어 패키징
디지털 저작권 관리 (DRM; Digital Right Management)
- 저작권자가 배포한 디지털 컨텐츠가 의도한 용도로만 사용되도록 관리, 보호 하는 기술
- 구성 요소
- 클리어링 하우스 (Clearing House) : 저작권에 대한 사용권한, 라이선스 발급, 사용량에 따른 결제 관리등 수행
- 콘텐츠 제공자: 콘텐츠를 제공하는 저작권자
- 패키저 : 콘텐츠를 메타데이터와 함께 배포 가능한 형태로 묶어 암호화하는 프로그램
- 콘텐츠 분배자 : 암호화된 콘텐츠를 유통하는 곳이나 사람
- DRM 컨트롤러 : 배포된 콘텐츠의 이용 권한을 통제하는 프로그램
- 보안 컨테이너 : 콘텐츠 원본을 안전하게 유통하기 위한 전자적 보안 장치
- 기술 요소
- 암호화
- 키관리
- 식별 기술
- 저작권 표현
- 정책 관리
- 크랙 방
소프트웨어 버전 등록
형상 관리 기능
- 형상 식별 : 형상 관리 대상에 이름과 관리번호를 부여하고, 계층(Tree)구조로 구분하여 수정 및 추적이 용이하도록 하는 작업
- 버전 제어 : SW업그레이드나 유지 보수 과정에서 생성된 다른 버전의 형상 항목을 관리하고, 이를 위해 특정 절차와 도구(Tool)를 결합시키는 작업
- 형상 통제(변경관리) : 식별된 형상 항목에 대한 변경 요구를 검토하여 현재의 기준선(Base Line)이 잘 반영될 수 있도록 조정하는 작업
- 형상 감사 : 기준선의 무결성을 평가하기 위해 확인, 검증, 검열 과정을 통해 공식적으로 승인하는 작업
- 형상 기록(상태 보고) : 형상의 식별, 통제, 감사 작업의 결과를 기록 관리하고 보고서를 작성
* 무결성 : 결점이 없다는 것으로, 정해진 기준에 어긋나지 않고 조건을 충실히 만족하는 정도
주요 기능
- 저장소 (Repository)
- 가져오기 (Import)
- 체크아웃 (Check-Out) : 프로그램을 수정하기 위해 저장소에서 파일을 받아옴
- 체크인 (Check-In) : 체크아웃 한 파일의 수정을 완료한 후 저장소의 파일을 새로운 버전으로 갱신
- 커밋
- 동기화
4장 애플리케이션 테스트 관리
애플리케이션 테스트
검증(Verification)과 확인(Validation)
- 검증 (Verification) : 소프트웨어가 요구사항에 부합하게 구현되었음을 보장하는 활동
- 확인 (Validation) : 소프트웨어가 고객의 의도에 따라 구현되었음을 보장하는 활동
검증 -> 개발자
확인 -> 사용자
파레토 법칙
- 테스트로 발견된 80%의 오류는 20%에 해당하는 코드(모듈)에서 발견된다.
살충제 패러독스 (Pesticide Paradox)
- 살충제를 지속적으로 뿌리면 벌레가 내성이 생겨 죽지 않음
- 동일한 TC로 동일한 테스트를 반복하면 더이상 결함이 발견되지 않음
- 이를 방지하기 위해 TC를 지속적으로 보안 및 개선해야 함
오류-부재의 궤변
- SW의 결함을 모두제거해도 사용자의 요구사항을 만족시키지 못하면 해당 소프트웨어는 품질이 높다고 할 수 없다.
애플리케이션 테스트의 분류
프로그램 실행 여부
- 정적 테스트
- 프로그램을 실행하지 않고 명세서나 코드를 대상으로 분석하는 테스트
- 워크스루, 인스펙션, 코드검사 등
- 동적 테스트
- 프로그램을 실행하여 오류를 찾음, 소프트웨어 개발의 모든 단계에서 테스트 수행 가능
- 블랙박스 테스트, 화이트박스 테스트
워크스루 (Walkthrough)
- 요구사항 명세서 작성자를 포함하여 사전 검토한 후에 짧은 검토 회의를 통해 결함을 발견
- 사용사례를 확장하여 명세하거나 설계 다이어그램, 원시코드, 테스트 케이스 등에 적용할 수 있다.
- 복잡한 알고리즘 또는 반복, 실시간 동작, 병행 처리와 같은 기능이나 동작을 이해하려고 할 때 유용하다.
- 단순한 테스트 케이스를 이용하여 프로덕트를 수작업으로 수행
인스펙션 (Inspection)
- 요구사항 명세서 작정자를 제외한 다른 검토 전문가들이 요구사항 명세서를 확인하면서 결함을 발견.
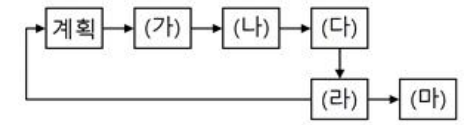
가 - 사전 교육
나 - 준비
다 - 인스펙션 회의
라 - 수정
마 - 후속조
목적에 따른 테스트
- 회복(Recovery) 테스트 : 시스템에 여러가지 결함을 주어 실패하도록 한 후 올바르게 복구되는지 확인
- 안전(Security) 테스트 : 시스템에 설치된 시스템 보호 도구가 불법적인 침입으로부터 시스템을 보호할 수 있는지 확인
- 강도(Stress) 테스트 : 시스템에 과도한 정보량이나 빈도 등을 부과하여 과부하시에도 정상적으로 실행되는지 확인
- 성능(Performance) 테스트 : 실시간 성능이나 전체적인 효율성을 진단하는 테스트, 응답시간, 처리량 등 확인
- 구조(Structure) 테스트 : SW 내부의 논리적인 경로, 소스 코드의 복잡도 등 평가
- 회귀(Regression) 테스트 : SW의 변경 또는 수정된 코드에 새로운 결함이 없음을 확인
- 병행(Parallel) 테스트 : 변경된 SW와 기존 SW에 동일한 데이터를 입력하여 결과를 비교
테스트 기법에 따른 애플리케이션 테스트
화이트박스 테스트
- 모듈의 원시코드를 오픈시킨 상태에서 원시코드의 논리적인 모든 경로를 테스트
- 테스트 과정의 초기에 적용된다.
- 화이트박스 테스트의 이해를 위해 논리흐름도(Logic_Flow Diagram)을 이용
- 테스트 데이터를 이용해 실제 프로그램을 실행함으로써 오류를 찾는 동적 테스트(Dynamic Test)에 해당
- 테스트 데이터를 선택하기 위해 검증기준(Test Coverage)을 정한다.
화이트박스 테스트 종류
- 기초 경로 검사
- 대표적인 화이트박스 테스트
- TC설계자가 절차적 설계의 논리적 복잡성을 측정할 수 있게 해주는방법
- 테스트 측정 결과는 실행 경로의 기초를 정의하는 지침으로 사용
- 제어 구조 검사
- 조건 검사 : 프로그램 모듈 내에 있는 논리적 조건을 테스트하는 방법
- 루프 검사 : 프로그램의 반복구조에 초점을 맞춘 방법
- 데이터 흐름 검사 : 변수의 정의와 변수 사용 위치에 초점을 맞춤
화이트박스 테스트의 검증 기준
- 문장 검증 기준 : 코드의 모든 구문이 한 번 이상 수행되도록 테스트 케이스 설계
- 분기 검증 기준 : 결정 검증 기준이라고도 함. 소스코드의 모든 조건문에 대해 조건이 True인 경우와 False인 경우가 한번이상 수행되도록 설계
- 조건 검증 기준 : 조건문에 포함된 개별 조건식의 결과가 True/False인 경우가 한번이상 수행되도록
- 분기/조건 기준 : 분기 검증기준과 조건 검증 기준을 모두 만족하는 설계
블랙박스 테스트
- 프로그램 구조를 고려하지 않는다.
- 소프트웨어 인터페이스에서 실시됨
- 부정확하거나 누락된 기능, 인터페이스 오류, 자료 구조나 외부 DB접근에 따른 오류, 행위나 성능 오류, 초기화와 종료 오류 등을 발견하기 위해 후반부에 적용
- 기능 테스트
블랙박스 테스트의 종류
- 동치 분할 검사 (동치 클래스 분해) : 입력 자료에 초점을 맞춰 TC를 만들고 검사하는 방법. 동등 분할 기법이라고도 함
- 경계값 분석 : 경계값에서 오류가 발생될 확률이 높다는 점을 이용
- 원인-효과 그래프 검사 : 입력 데이터간의 관계와 출력에 영향을 미치는 상황을 체계적으로 분석한 다음 효용성이 높은 TC를 선정하여 검사하는 방법
- 오류 예측검사 : 과거의 경험이나 확인자으 감각으로 테스트하는 방법
- 비교 검사 : 여러 버전의 프로그램에 동일한 테스트 자료를 제공하여 동일한 결과가 출력되는지 확인하는 방법
개발 단계에 따른 애플리케이션 테스트
소프트웨어 생명 주기의 V-모델
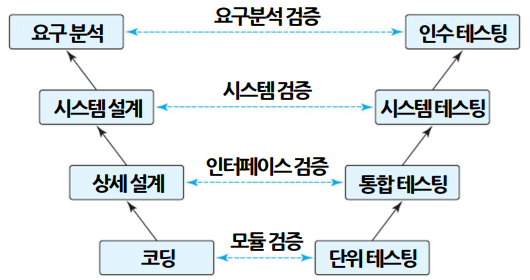
단위 테스트 (Unit Test)
- 코딩 직후 모듈이나 컴포넌트에 초점을 맞춰 테스트하는 것
- 인터페이스, 외부적 IO, 자료구조, 독립적 기초 경로, 오류 처리경로, 경계조건 등 검사
- 사용자의 요구사항을 기반으로 한 기능성 테스트를 최우선으로 수행
- 구현 단계에서 각 모듈의 개발을 완료한 후 개발자가 명세서의 내용대로 정확히 구현되었는지 테스트한다.
- 모듈 내부의 구조를 구체적으로 볼 수 있는 구조적 테스트를 주로 시행
- 테스트할 모듈을 호출하는 모듈도 있고, 테스트할 모듈이 호출하는 모듈도 있다.
- 단위 테스트로 발견 가능한 오류
- 알고리즘 오류에 따른 원치 않은 결과
- 탈출구가 없는 반복문
- 틀린 계산 수식에 의한 잘못된 결
단위 테스트 도구
- CppUnit - C++ 단위 테스트 도구
- JUnit - 자바 단위 테스트 도구
- HttpUnit - 웹 브라우저 없이 웹 사이트 테스트를 수행하는 오픈 소스 소프트웨어 테스트 프레임워크
인수 테스트 (Acceptance Test)
- 개발한 SW가 사용자의 요구사항을 충족하는지에 중점을 두고 테스트
- 개발한 SW를 사용자가 직접 테스트
- 인수 테스트에 문제가 없으면 사용자는 SW를 인수하고 프로젝트 종료
- 사용자 인수테스트 : 사용자가 시스템 사용의 적절성 여부 확인
- 운영상의 인수 테스트 : 시스템관리자가 시스템 인수시 수행하는 테스트. 백업/복원 세스템, 재난복구, 사용자 관리, 정기정검 등 확인
- 계약 인수 테스트 : 계약상의 인수/검수 조건 준수 여부 확인
- 규정 인수 테스트 : SW가 정부 지침, 법규, 규정에 맞게 개발되었는지 확인
- 알파 테스트 : 개발자의 장소에서 사용자가 개발자 앞에서 행하는 ㅔ스트
- 베타 테스트 : 선정된 최종 사용자가 여러 명의 사용자 앞에서 행하는 테스트, 필드 테스팅이라고도 함
* 알파/베타 테스트 게임으로 생각하면 편함.
통합 테스트(Integration Test)
- 상향식 통합 테스트 (Bottom Up Integration Test)
- 프로그램의 하위 모듈에서 상위 모듈 방향으로 통합
- 하나의 주요 제어 모듈과 관련된 종속 모듈의 그룹인 클러스터(Cluster)필요
- 하향식 통합 테스트(Top Down Integration Test)
- 상위 모듈에서 하위 모듈 방향으로 통합
- 깊이 우선 통합법, 넓이 우선 통합법 사용
- 초기부터 사용자에게 시스템 구조를 보여줌
테스트 드라이버 (Test Driver)
- 필요 데이터를 인자를 통해 넘겨주고, 테스트 완료 후 그 결과값을 받는 역할을 하는 가상의 모듈
테스트 스텁 (Test Stub)
- 인자를 통해 받은 값을 가지고 수행한 후 그 결과를 테스트할 모듈에 넘겨주는 역할
| 구분 | 드라이버 | 스텁 |
| 개념 | 테스트 대상의 하위 모듈을 호출하는 도구. 매개 변수를 전달하고, 모듈 테스트 수행 후의결과를 도출 |
제어 모듈이 호출하는 타 모듈의 기능을 단순히 수행하는 도구 일시적으로 필요한 조건만을 가지고 있는 시험용 모듈 |
| 필요 시기 | 상위 모듈 없이 하위 모듈이 있는 경우 하위 모듈 구동 | 상위 모듈은 있지만 하위 모듈이 없는 경우 하위 모듈 대체 |
| 테스트 방식 | 상향식 | 하향식 |
| 공통점 | 소프트웨어 개발과 테스트를 병행할 경우 이용 | |
| 차이점 | 이미 존재하는 하위 모듈과 존재하지 않는 상위 모듈간의 인터페이스 역할 소프트웨어 개발이 완료되면 드라이버는 본래의 모듈로 교체 |
일시적으로 필요한 조건만을 가지고 임시로 제공되는 가짜 모듈의 역할 시험용 모듈이기 때문에 일반적으로 드라이버보다 작성하기 쉬움 |
테스트 케이스 / 테스트 오라클
테스트 오라클
- 테스트 결과가 올바른지 판단하기 위해 사전에 정의된 참 값을 대입하여 비교하는 방법
- 참(True) 오라클 : 모든 테스트케이스의 입력 값에 대해 기대하는 결과를 제공하는 오라클, 발생된 모든 오류를 검출 할수 있음
- 샘플링 오라클 : 특정한 몇몇 테스트케이스의 입력값들에 대해서만 기대하는 결과를 제공
- 추정(Heuristic) 오라클: 특정 테스트 케이스의 입력 값들에 대해 기대하는 결과를 제공하고, 나머지 입력 값들에 대해서는 추정하는 방법
- 일관성 검사(Consistent) 오라클 : 애플리케이션의 변경이 있을 때, 테스트 케이스의 수행 전과 후의 결과 값이 동일한지 확인
테스트 케이스 자동화 도구
테스트 케이스 생성 도구
- 자료 흐름도
- 기능 테스트
- 입력 도메인 분석
- 랜덤 테스트
복잡도
시간 복잡도
- 빅오 표기법 : 최악
- 세타 표기법 : 평균
- 오메가 표기법 : 최상
알고리즘 별 시간복잡도
- O(1) : 스택 삽입(Push), 삭제(Pop)
- O(log₂n) : 이진 트리, 이진 탐색
- O(n) : for문
- O(nlog₂n) : 힙 정렬, 2-way 합병 정렬
- O(n²) : 삽입 정렬, 쉘 정렬, 선택 정렬, 버블 정렬, 퀵 정렬
- O(2ⁿ) : 피보나치 수열
순환 복잡도
순환 복잡도 (Cyclomatic Complexity), 맥케이브 순환도 (McCabe's Cyclomatic), 제어 흐름도 이론에 기초를 둠
제어 흐름도 G에서 순환 복잡도 V(G)
V(G) = E - N + 2
E : 화살표 수
N : 노드의 수
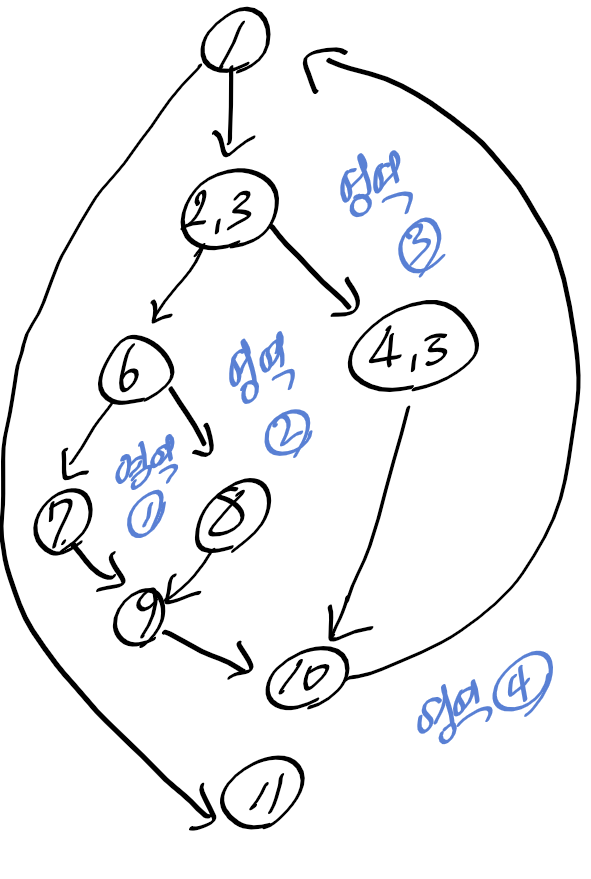
순환복잡도 V(G) = 화살표수 (11) - 노드의 수(9) + 2 = 4
영역의 수 = 내부 영역(1, 2, 3) + 외부 영역(4) = 4
아래 제어 흐름도그래프의 McCabe의 Cyclomatic 수는?
영억 4개 -> 4
애플리케이션 성능 개선
소스 코드 최적화
- 클린 코드 : 누구나 쉽게 이해하고 수정 및 추가할 수 있는 단순 명료한 코드, 잘 작성된 코드
- 나쁜 코드
- 스파게티 코드 : 코드의 로직이 복잡하게 얽힌 코드
- 외계인 코드(Alien Code) : 아주 오래되거나 참고문서 또는 개발자가 없어 유지 보수 작업이 어려운 코드
클린 코드 작성 원칙
- 가독성 : 누구나 코드를 쉽게 읽을수 있도록
- 단순성 : 코드를 간단하게 작성
- 의존성 배제 : 코드가 다른 모듈에 미치는 영향을 최소화
- 중복성 최소화 : 코드의 중복을 최소화
- 추상화 : 상위 클래스/메소드/함수에서는 간략하게 어플리케이션의 특성을 나타내고, 상세 내용은 하위 클래스/메소드/함수에서 나타냄
소스코드 품질 분석 도구
- 정적 도구 : 작성한 코드를 실행하지 않고 코딩 표준이나 코딩 스타일, 결함 등을 확인하는 코드 분석 도구
- pmd, cppcheck, SonarQube, checkstyle, ccm, cobertura 등
- 동적 도구 : 소스 코드를 실행하여 코드에 존재하는 메모리 누수, 스레드 결함 등 분석
- Avalanche, Valgrind
5장 인터페이스 구현
EAI (Enterprise Application Integration)
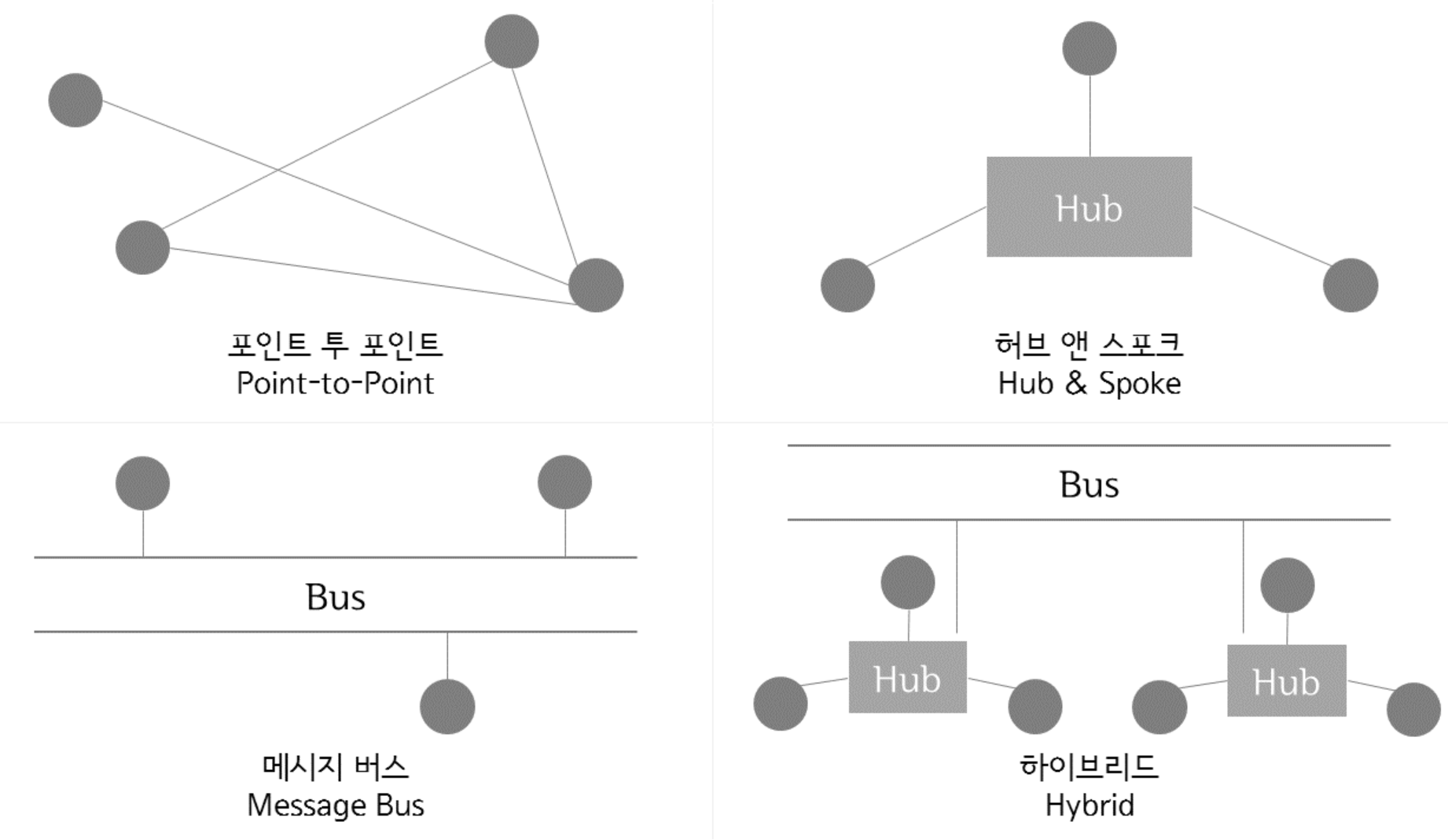
구축 유형
- Point-to-Point
- 기본적인 애플리케이션 통합방식, 1:1로 연결
- 변경 및 재사용 어려움
- Hub & Spoke
- 단일 접점인 허브 시스템을 통해 데이터를 전송하는 중앙 집중형 방식
- 확장 및 유지보수 용이
- 허브 장애 발생시 시스템전체에 영향
- Message Bus (ESB)
- 애플리케이션 사이에 미들웨어를 두어 처리하는 방식
- 확장성이 뛰어나며대용량 처리 가능
- Hybrid
- Hub & Spoke + Message Bus 혼합방식
- 그룹 내에서는 Hub & Spoke, 그룹 간에는 Message Bus
- 필요한 ㄱ여우 한가지 방식으로 EAI 구현 가능
- 데이터 병목현상 최소화
ESB
- EAI와 유사하지만 애플리케이션보다는 서비스중심의 통합 지향
- 특정 서비스에 국한되지 않고 범용적으로 사용하기위해 애플리케이션과 결합도를 약하게
- 관리 및 보안 유지 쉬움, 높은 수준의 품질 지원 가능
XML
- 다목적 마크업 언어
- HTML의 문법이 각 웹 브라우저에서 상호 호환적이지 못한 문제와 SGML의 복잡함을 해결하기 위해 개발됨
- SGML : Stand Generalized Markup Language - 텍스트, 이미지, 오디오 및 비디오 등 멀티미디어 전자문서들을 다른 기종의 시스템들과 정보 손시 ㄹ없이 효율적으로 전송 저장 및 자동 처리하기위한 언어
인터페이스 보안
인터페이스 보안 기능
네트워크 영역
- 인터페이스 송수신 간 스니핑(Sniffing) 등을 이용한 데이터 탈취 및 변조 위협을 방지하기 위해네트워크 트래픽에 대한 암호화 설정
- IPSec, SSL, S-HTTP 등
- IPSec : 네트워크 계층에서 IP 패킷 단위의 데이터 변조 방지 및 은닉 기능을 제공하는 프로토콜
- SSL : TCP/IP 계층과 애플리케이션 계층 사이
- S-HTTP : 클라이언트/서버 간
데이터 무결성 검사 도구
- Tripwire
- AIDE
- Samhain
- Claymore
- Slipwire
- Fcheck 등
인터페이스 구현 검증
구현 검증 도구
- xUnit
- JUnit, CppUnit, NUnit, HttpUnit 등 다양한 언어에 적용되는 단위 테스트 프레임워크
- 같은 테스트 코드를 여러번 작덩되지 않게 도와주고, 테스트마다 예상 결과를 기억하 ㄹ필요가 없게 하는 자동화된 해법을 제공
- STAF
- 서비스 호출 및 컴포넌트 재사용 등 다양한 환경을 지원하는 테스트 프레임워크
- FitNesse
- 웹 기반 테스트케이스 설계, 실행, 결과 확인 등지원하는 테스트 프레임워크
- NTAF
- FitNesse의 장점인 협업 기능과 STAF의 장점인 재사용 및 확장성을 통합한 NHN(Naver)의 테스트 자동화 프레임워크
- Selenium
- 다양한 브라우저 및 개발 언어를 지원하는 웹 애플리케이션 테스트 프레임워크
- watir
- Ruby를 사용하는 애플리케이션 테스트 프레임워크
- Ruby를 사용하는 애플리케이션 테스트 프레임워크
위험 모니터링
- 위험 요소 징후들에 대하여 지속적으로 인지하는 것
컴파일 (Compile)
- 우저인 언어로 작성된 컴퓨터 프로그램을 다른 언어의 동등한 프로그램으로 변환하는 기능
- 고급언어 (사람이 인식하는 언어)에서 저급언어(기계어)로 변환하는 기능
최악의 경우 트리 검색 시간복잡도
- 이진 탐색트리 : O(n)
- AVL 트리 : O(logn)
- 2-3 트리 : O(log3n)
- 레드 블랙 트리 : O(logn)
힙 정렬(Heap Sort) 시간복잡도
- 최적, 평균, 최악 모두 O(nlog2n)
N개의 데이터 시간 복잡도
- O(Nlog2N) : 퀵정렬, 합병정렬 -> 선형 로그형 복잡도
- O(N²) : 버블정렬, 삽입정렬, 선택정렬
* 정렬된 경우 버블정렬과 삽입정렬은 O(N)
'정보처리기사 > 필기' 카테고리의 다른 글
| 자주 틀리는 항목 (3) | 2024.02.29 |
|---|---|
| 정보처리기사 필기 공부 5과목 (정보시스템 구축관리) (0) | 2024.02.02 |
| 정보처리기사 필기 공부 4과목 (프로그래밍 언어 활용) (1) | 2024.01.31 |
| 정보처리기사 필기 공부 3과목 (데이터베이스 구축) (0) | 2024.01.29 |
| 정보처리기사 필기 공부 1과목 (소프트웨어 설계) (0) | 2024.01.17 |




댓글